Prima di iniziare diamo una definizione di HUBERT per poi passare all’analisi del problema e la proposta per la sua risoluzione.
HUBERT: Modello Fine-Tuned basato su BERT addestrato da UNICO in grado di comprendere e categorizzare automaticamente le query degli utenti, garantendo che la risposta venga gestita utilizzando il modello più adeguato. Questo modello AI mira a migliorare l’efficienza e la precisione nella risoluzione delle richieste degli utenti, personalizzando l’interazione a seconda delle necessità.
Problema
Il grande limite dei modelli di text classification attualmente per quanto riguarda lo use case di UNICO è la comprensione delle sottigliezze nelle domande, date le categorie di contesti molto limitate. Questo comporta una possibilità di errore nella comprensione del contesto e dunque la scelta del modello errato. Attualmente le categorie assegnabili ed analizzate da artificialanalysis che interessano il nostro business sono 4:
- GPQA (Scientific Reasoning & Knowledge)
- MMLU (Reasoning & Knowledge)
- MATH (Quantitative Reasoning)
- CODE (Human Evaluation)
In aggiunta ARIA (Action Recognition & Intelligent Assesment) definito da UNICO per comprendere quando un utente intende utilizzare un’action e che attualmente utilizza sempre gpt-4o.
Ci sono però molti casi in cui la scelta della categoria è complicata e sbagliare è facile. Pensiamole come Domande “Quantiche”, nome scelto data l’esistenza di categorie multiple allo stesso tempo e poniamo di seguito un esempio:
Quali furono le cause della crisi economica del 1929?
Questa domanda tende verso l’economia dunque GPQA, data la richiesta di un’analisi delle cause, ma potrebbe essere scambiata per una domanda storica e l’AI potrebbe definirla come MMLU. Per questo per il fine-tuning di HUBERT e l’ottimizzazione del focus principale di UNICO, ovvero la scelta del modello migliore in base alla domanda dell’utente, si pone la necessità di cambiare approccio.
Soluzione
“L’idea sarebbe quella di dare a HUBERT più libertà di scelta per i contesti compresi in modo che associ meglio le piccole differenze, in categorie definite da noi, per poi andarle ad astrarre nelle categorie di base misurabili in cui sappiamo quale modello scegliere”
Suddividendo le categorie di contesti misurabili ma difficilmente assegnabili (GPQA, MMLU, MATH, CODE, ARIA) in una serie di sottocategorie non misurabili ma facilmente assegnabili, offre una maggiore flessibilità e precisione nella selezione del modello, migliorando significativamente la capacità del sistema di gestire contesti complessi e sottilmente diversi. Di seguito alcuni esempi per ogni categoria:
- GPQA:
- Health
- Biology
- Economics
- Technology
- MMLU:
- Summary
- BasicQuestion
- Historical
- Ethics
- ARIA:
- GetData
- MissingInformations
- PersonalDataAnalysis
- DataPrediction
- MATH:
- Geometry
- Trigonometry
- LinearAlgebra
- Probability
- CODE:
- Algorithm
- Debugging
- Optimization
- CodeExplaination
Come si può vedere possiamo definire noi a quale categoria analizzabile assegnare ciascuna categoria astratta, data la soggettività di alcuni argomenti (vedi Technology assegnata a GPQA). Una volta definite, queste sottocategorie verranno mappate manualmente sulle cinque categorie misurabili principali direttamente all’interno di UNICO, ritornando allo stato attuale delle cose, ma con una maggiore precisione. Questo ci permetterà di:
- Ridurre l’astrazione eccessiva che può portare a errori nella comprensione del contesto.
- Rendere più flessibile e accurata la selezione del modello migliore per ogni query.
- Evolvere dinamicamente il sistema aggiungendo nuove sottocategorie man mano che emergono nuove tipologie di query e sottigliezze in quelle già esistenti, addestrando HUBERT solo a riconoscere la nuova categoria astratta ed incrementando la sua precisione.
Di seguito uno schema per comprendere al meglio il nuovo approccio:
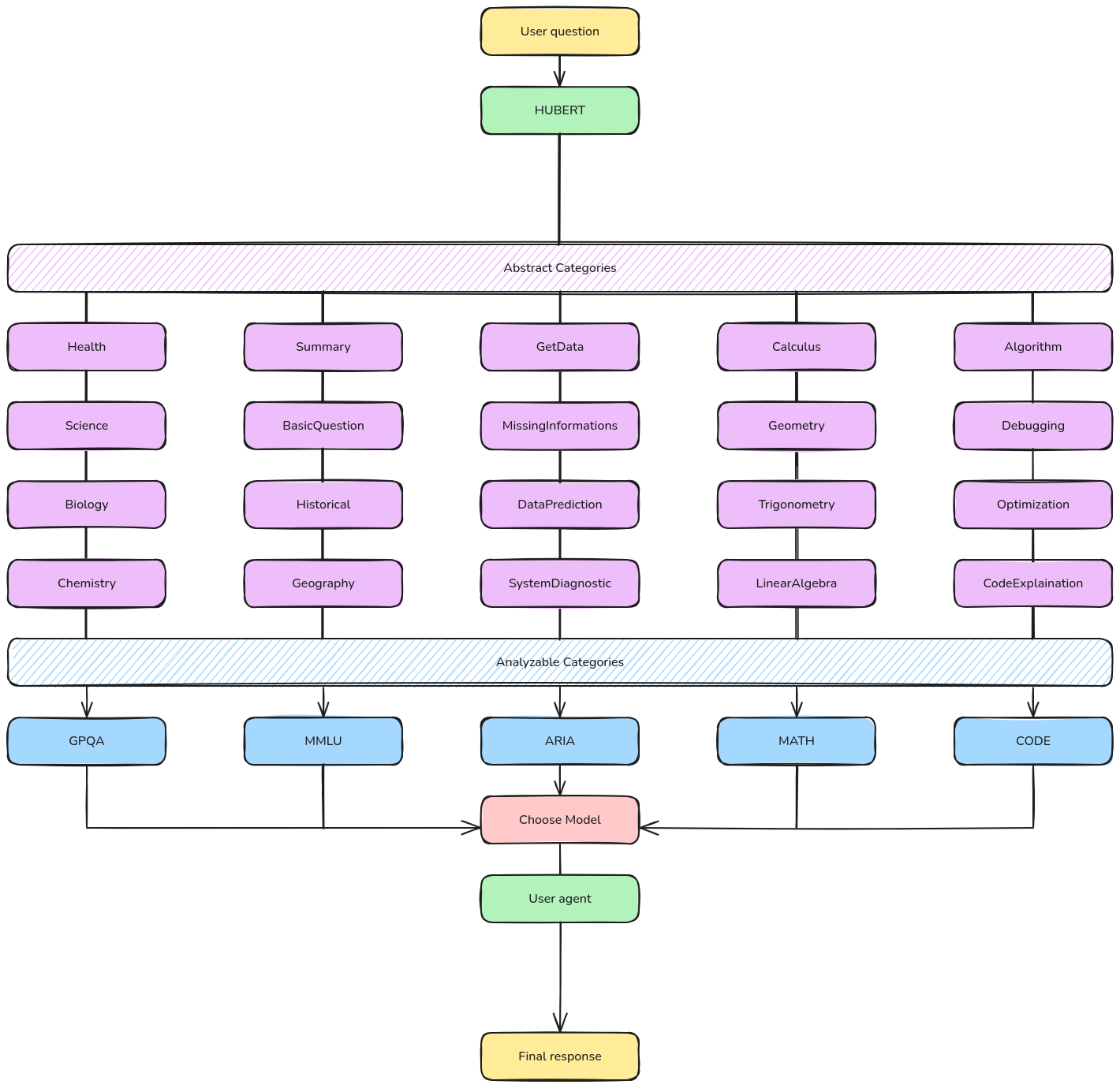
In conclusione crediamo che questo approccio migliorerà drasticamente la comprensione contestuale di HUBERT, riducendo gli errori dovuti all’eccessiva astrazione e garantendo una selezione ottimale del modello per ogni scenario. Un ambiente di categorizzazione più raffinato risolverà i problemi attuali, rendendo HUBERT uno strumento più efficace e scalabile nel tempo.